Breast Cancer Diagnostics
This project applies supervised machine learning to predict whether a breast tumor is benign (B) or malignant (M) using the Breast Cancer Wisconsin (Diagnostic) dataset from the UCI Machine Learning Repository.
Highlights:
Ensemble model achieved over 99% accuracy on the test set.
– Perfect sensitivity (no malignant cases misclassified).
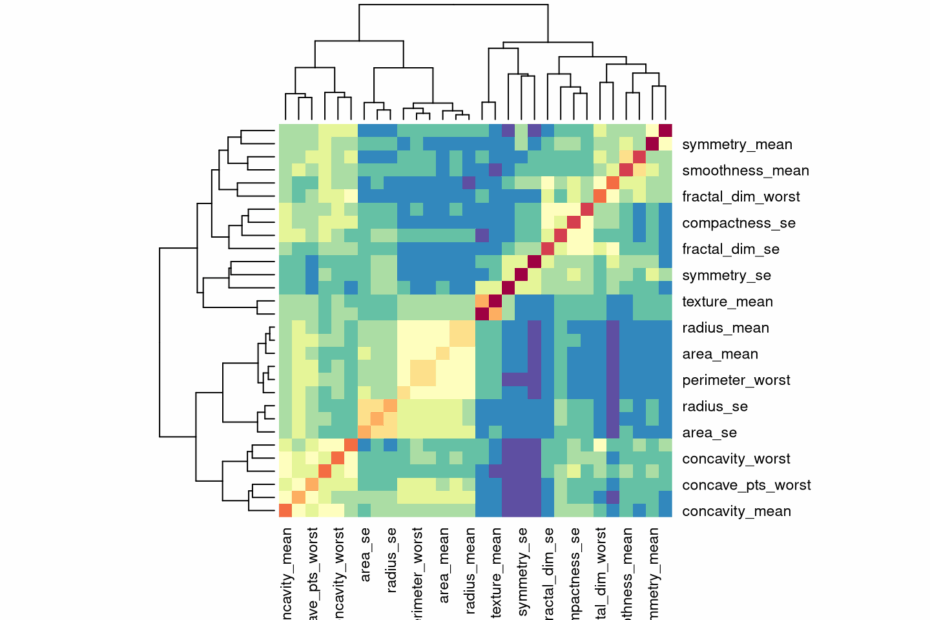
– Most predictive features: Concave Points (Worst), Radius (Worst), Perimeter (Worst).
Demonstrates how ensemble learning methods can enhance diagnostic precision and reduce false negatives in medical classification tasks.